รู้จัก Amazon S3 มันคืออะไร? ทำไมต้องเก็บข้อมูลลง Bucket? ข้อมูลหลุดได้อย่างไร?
Amazon S3 ย่อมาจากคำว่า Simple Storage Service มันคือบริการเก็บข้อมูลบนคลาวด์ของ Amazon Web Services (AWS) ซึ่งเป็นผู้ให้บริการคลาวด์อันดับหนึ่งของโลก นอกจากนี้ S3 ยังถือเป็นบริการตัวแรกสุดของ AWS ด้วย โดยเปิดตัวมาตั้งแต่ปี 2006 หรือ 12 ปีก่อน

S3 คืออะไร? ทำหน้าที่อย่างไร?
Amazon S3 คือบริการเก็บข้อมูลแบบวัตถุ (ออบเจคต์) มีชื่อเรียกอย่างเป็นทางการว่า object storage
รูปแบบของแอพพลิเคชันในอดีต (ยุคก่อนคลาวด์) เราคุ้นเคยกับการเก็บข้อมูลในรูปแบบของไฟล์ (file) หรือเก็บลงฐานข้อมูล (relational database) โดยขึ้นกับประเภทการใช้งาน หากข้อมูลต้นทางมาในรูปแบบของไฟล์ เช่น รูปภาพ, ไฟล์เอกสาร (doc/pdf) การเก็บข้อมูลจะเก็บในรูปแบบไฟล์ในโฟลเดอร์ที่กำหนดไว้
แต่ในยุคของคลาวด์ รูปแบบของแอพพลิเคชันเริ่มซับซ้อนมากขึ้น เกิดการแยกส่วนระหว่างการประมวลผล (compute) และการเก็บข้อมูล (storage) ออกจากกัน โดยงานสองส่วนไม่จำเป็นต้องอยู่ที่เดียวกันก็ได้ เราอาจเก็บข้อมูลไว้บนบริการคลาวด์รายหนึ่ง แล้วนำไปประมวลผลบนคลาวด์อีกรายหนึ่งก็ย่อมทำได้
AWS มีบริการประมวลผลชื่อว่า EC2 (ย่อมาจาก Elastic Compute Cloud) และมีบริการเก็บข้อมูลให้เลือกหลายตัว ขึ้นกับประเภทการใช้งาน โดย S3 เป็นบริการตัวหนึ่งในนั้น หน้าที่ของมันคือเก็บข้อมูลแบบออบเจคต์ (object storage) หรือการเก็บวัตถุเป็นชิ้นๆ เทียบได้กับการเก็บไฟล์นั่นเอง (ส่วนการเก็บแบบฐานข้อมูลก็มีบริการอื่นอย่าง Amazon RDS หรือ DynamoDB ซึ่งจะไม่พูดถึงในที่นี้)
ทำไมเราจึงต้องเก็บข้อมูลลง S3
เหตุผลในการเก็บข้อมูลลง S3 มีหลากหลาย ตั้งแต่ความสามารถในการรองรับข้อมูลจำนวนมาก (scalability) ในระดับที่องค์กรทั่วไปไม่สามารถมีได้เท่ากับ AWS, ความน่าเชื่อถือในระบบคลาวด์ของ AWS การันตีว่าข้อมูลจะเข้าถึงได้เสมอ (ด้วยพลังวิศวกรรมของ AWS ที่เป็นคลาวด์อันดับหนึ่งของโลก), การมีเซิร์ฟเวอร์ของ S3 กระจายตัวอยู่ทั่วโลก ให้บริการลูกค้าได้จากทุกภูมิภาค ไปจนถึงความสะดวกในการบริหารจัดการ สำหรับองค์กรที่ไม่อยากมีภาระในการดูแลเซิร์ฟเวอร์เอง
ส่วนรูปแบบการใช้งาน S3 ก็มีหลากหลายเช่นกัน ตั้งแต่การเก็บข้อมูลทั่วไป การสำรองข้อมูล (แทนการสำรองลงเทปหรือข้ามไซต์ ก็เปลี่ยนมาเก็บลงคลาวด์แทน) หรือการเก็บข้อมูล Big Data เพื่อใช้วิเคราะห์
สำหรับแอพพลิเคชันยุคใหม่ๆ ที่เริ่มต้นในยุคคลาวด์ การเลือกเก็บข้อมูลลง S3 (หรือบริการเทียบเคียงของคู่แข่งอย่าง Azure หรือ Google Cloud) จึงเป็นเรื่องสมเหตุสมผล สตาร์ตอัพและบริษัทจำนวนมากในไทยก็เป็นลูกค้าของบริการในลักษณะนี้
ความน่าเชื่อถือและความปลอดภัยของ S3
เนื่องจาก S3 เป็นบริการที่เปิดมายาวนาน ได้รับความน่าเชื่อถือมาก จึงมีองค์กรระดับโลกเลือกเก็บข้อมูลลง S3 เช่น Netflix หรือ Airbnb รวมถึงหน่วยงานรัฐบาลของสหรัฐอย่างกระทรวงกลาโหม
ส่วนในแง่ความปลอดภัย ก็ต้องบอกว่าโครงสร้างพื้นฐานของ AWS มีความปลอดภัยสูงพอในระดับที่สามารถบริการกับลูกค้าองค์กรขนาดใหญ่จำนวนมาก และผ่านมาตรฐาน (compliance) ตามข้อกำหนดด้านกฎหมายและกฎระเบียบในประเทศต่างๆ (รายละเอียด)
อะไรคือ Bucket
ในการใช้งาน S3 จำเป็นต้องสร้าง “ถัง” (bucket) สำหรับเก็บข้อมูลขึ้นก่อน คำอธิบายแบบรวบรัดของ bucket เปรียบได้กับโฟลเดอร์ชั้นนอกสุด เพื่อให้เราจัดหมวดหมู่ข้อมูลได้เป็นระเบียบ และไม่นำข้อมูลที่ไม่เกี่ยวข้องกัน (เช่น ใช้งานคนละโครงการ) มายุ่งกัน
ข้อจำกัดของ bucket คือแต่ละถังต้องมีชื่อเฉพาะของตัวเอง และห้ามซ้ำกันในระบบทั้งหมดของ S3 ด้วย ผู้ใช้แต่ละรายสามารถตั้งชื่อ bucket เป็นอะไรก็ได้ (แค่ว่าห้ามซ้ำกับ bucket ที่มีอยู่แล้วในระบบ) ชื่อของ bucket ที่ตั้งไว้จะกลายเป็นส่วนหนึ่ง URL สำหรับให้เข้าถึงได้ ตัวอย่างเช่น https://myawsbucket.s3.amazonaws.com
เมื่อสร้าง bucket แล้ว ผู้ใช้ถึงสามารถเก็บข้อมูล (S3 เรียกว่า object) ลงในถังตามที่ต้องการใช้งาน
สิทธิการเข้าถึงข้อมูลใน Bucket
ตามปกติแล้ว เมื่อสร้าง bucket ขึ้นมาในระบบของ AWS แล้ว สิทธิการเข้าถึงข้อมูลทั้งหมดใน bucket นั้นจะถูกกำหนดมาเป็นแบบ “private” ตั้งแต่แรก แปลว่ามีเฉพาะผู้ใช้เจ้าของ bucket เท่านั้นที่สามารถเข้าถึงข้อมูลได้
จากนั้น เจ้าของ bucket อาจเปิดสิทธิการเข้าถึงข้อมูล (grant access permissions) ให้กับบุคคลอื่น (เช่น เพื่อนร่วมงาน ลูกค้า) ได้ในภายหลัง ผ่านเครื่องมือที่เรียกว่า policies and access control lists (ACLs)
ในแง่ความปลอดภัยแล้ว ข้อมูลใน bucket ควรจำกัดการเข้าถึงเฉพาะผู้ที่ได้รับอนุญาตเท่านั้น แต่เราก็สามารถตั้งค่า bucket ให้ “ทุกคน” เข้าถึงได้โดยไม่จำเป็นต้องล็อกอินใดๆ หรือที่เรียกว่าเป็น public bucket ซึ่งเหมาะสำหรับข้อมูลที่ตั้งใจเป็น public อยู่แล้ว เช่น ข้อมูลเว็บไซต์หรือเอกสารสำหรับเผยแพร่ต่อสาธารณะ
AWS มีนโยบายให้ผู้ใช้งาน S3 พึงรู้ตัวอยู่เสมอว่าข้อมูลใน bucket ใดบ้างที่เปิดเป็น public (ไม่ว่าจะตั้งใจหรือเผลอ) ผ่านเครื่องมือจัดการในระบบของ S3 เอง ตามภาพ (สีส้มหรามองเห็นได้ชัดเจน)
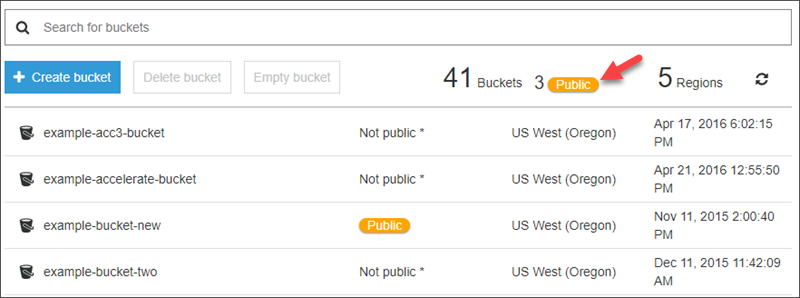
การสแกนหา Bucket ที่เปิดเป็น Public
อย่างไรก็ตาม ถึงแม้ว่าผู้ใช้เผลอเปิด S3 Bucket เป็น public แล้ว แต่ถ้าหากไม่รู้ชื่อ bucket หรือ URL ก็ยังไม่สามารถเข้าถึงข้อมูลใน bucket นั้นได้อยู่ดี เหตุนี้จึงมีแฮกเกอร์จำนวนมาก หาวิธีสแกนชื่อ bucket ในระบบของ AWS “เผื่อว่า” จะเจอ bucket ที่เป็น public และสามารถนำข้อมูลออกมาได้โดยไม่ต้องเสียเวลาเจาะระบบอะไรเลย
ในกรณีของ iTrueMart นั้น นักวิจัยด้านความปลอดภัยชื่อ Niall Merrigan ใช้เครื่องมือชื่อ Bucket Stream ซึ่งเป็นเครื่องมือที่เผยแพร่กันทั่วไป มาค้นหา public bucket ที่เปิดให้ทุกคนเข้าถึงได้ (รายละเอียดของเทคนิคที่ Bucket Stream ใช้จะไม่กล่าวถึงในที่นี้) เพื่อแจ้งเตือนเจ้าของ bucket นั้นให้รู้ตัว
การสแกนของเขา ทำให้ค้นเจอ bucket อันหนึ่ง (เขาไม่เปิดเผยชื่อ bucket) ที่มีโครงสร้างโฟลเดอร์ชื่อ truemoveh/idcard/YYYY/MM/FILENAME อยู่ในนั้น
ส่วนเหตุผลที่ bucket นี้เปิดข้อมูลเป็น public นั้นก็ไม่สามารถทราบได้